RocketMQ消息持久化
[toc]
什么是持久化
所谓持久化,就是把数据保存到可以永久保存的存储设备中,持久化的主要应用是将内存中数据存储到磁盘。
MQ为什么需要持久化
持久化,一是防止宕机时的数据丢失,二是可以在高峰期先将数据刷盘,然后再慢慢处理。
MQ如何持久化
- 依赖缓存,比如redis、ZeroMQ,由于分布式缓存的读写能力优于DB,如果你的需求是快产快消的即时消费场景,并且生产的消息立即被消费者消费掉,并且看中速度,那么用这种方式也ok。
- 数据库DB,Apache下的ActiveMQ支持数据库的持久化方式,可以实现JDBC消息存储,由于关系型数据库在数据量很大的情况下的IO读写能力会出现瓶颈,而且非常依赖于数据库。
- 文件系统,也就是RocketMQ采用的持久化方式,且主流的kafka、rabbitMQ也是采用这种方式,它是将消息刷盘到服务器的文件系统中。它能提供高可靠、高性能,除非MQ挂了或者服务器宕机,不然不会出现无法持久化的问题。
RocketMQ的持久化流程(存储流程)
- Producer 将消息发送到 Broker 后,Broker 会采用同步或者异步的方式把消息写入到 CommitLog。RocketMQ 所有的消息都会存放在 CommitLog 中,为了保证消息存储不发生混乱,对 CommitLog 写之前会加锁,同时也可以使得消息能够被顺序写入到 CommitLog,只要消息被持久化到磁盘文件 CommitLog,那么就可以保证 Producer 发送的消息不会丢失。
- CommitLog 持久化后,会把里面的消息 Dispatch 到对应的 ConsumeQueue 上,调用 CommitLogDispatcherBuildConsumeQueue,ConsumeQueue 相当于 Kafka 中的 Partition,是一个逻辑队列,存储了这个 Queue 在 CommitLog 中的起始 Offset,log 大小和 MessageTag 的 hashCode。
- 同时消息也被 Dispatch 到对应的 IndexFile 上,调用 CommitLogDispatcherBuildIndex 。 每次推送会休息1毫秒,然后继续,IndexService 调用 buildIndex 构建索引。
- 当消费者进行消息消费时,会先读取 ConsumerQueue,逻辑消费队列 ConsumeQueue 保存了指定 Topic 下的队列消息在 CommitLog 中的起始物理偏移量 Offset,消息大小、和消息 Tag 的 HashCode 值。
- 然后跟据相关的偏移量到CommitLog中读取消息。
RocketMQ的存储文件
Commitlog文件、ConsumeQueue文件、IndexFile文件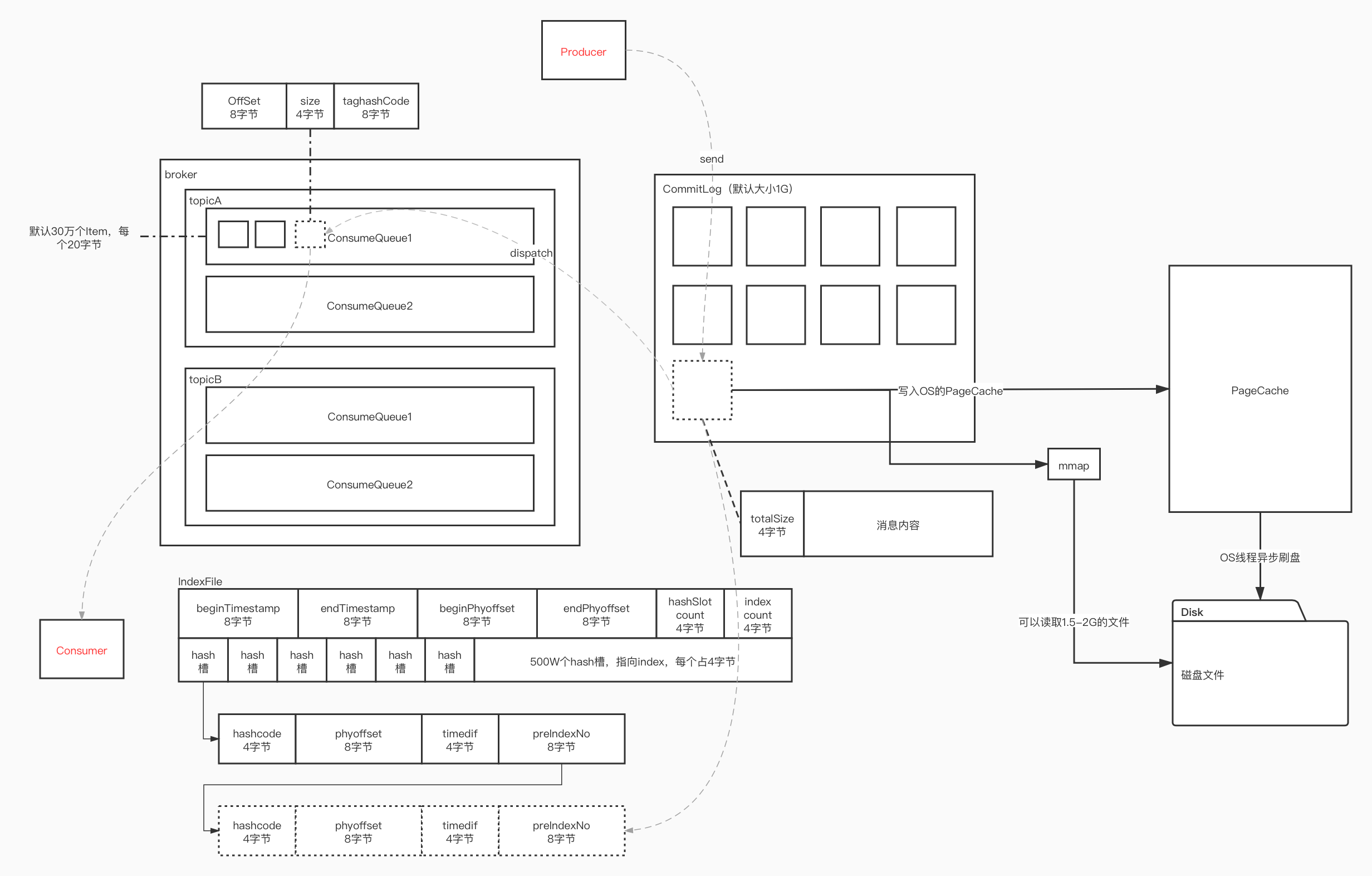
1. Commitlog文件
什么是CommitLog文件
commitlog文件的存储地址:$HOME\store\commitlog${fileName},每个文件的大小默认1G =102410241024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824,以此类推。
Commitlog是消息存储的物理文件,为了提高写入的效率,采取顺序写的策略(磁盘的顺序写入不需要重新寻址,效率很高,才机械硬盘中会更明显)。为了实现顺序写,RocketMQ把所有的主题的消息都会存储到同个Commitlog文件中。
什么是CommitLog条目
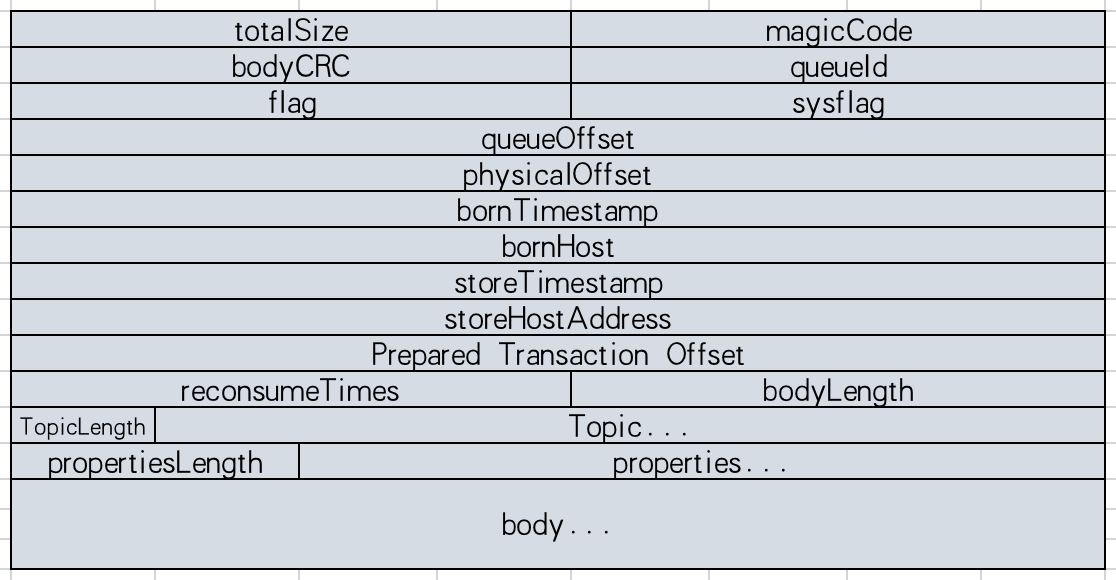
- TOTALSIZE: 该消息条目总长度,4字节
- MAGICCODE: 魔法值,固定0xdaa320a7,4字节
- BODYCRC: 消息体crc校验码,4字节
- QUEUEID: ComsumeQueue消息消费队列ID,4字节
- FLAG: 消息FLAG,预留给消费者的标识位,4字节
- QUEUEOFFSET: 消息在ComsumeQueue的偏移量,8字节
- PHYSICALOFFSET: 消息在CommitLog文件中的偏移量,8字节
- SYSFLAG: 消息系统FLAG,例如是否压缩、是否有事务消息,4字节
- BORNTIMESTAMP: 消息产生者调用消息发送API的时间戳,8字节
- BORNHOST: 消息发送者IP、端口号,8字节
- STORETIMESTAMP: 消息存储时间戳,8字节
- STOREHOSPTADDRESS: Broker服务器IP+端口号,8字节
- RECONSUMETIMES: 消息重试次数,4字节
- Prepare Transaction Offset: 事务消息物理偏移量,8字节
- BodyLength: 消息体长度,4字节
- Body: 消息体内容
- TopicLength: 主题存储长度,主题名称不能超过255个字符,1字节
- Topic: 主题内容
- PropertiesLength: 消息属性长度,表示消息属性长度不能超过65536个字符,2字节
- Properties: 消息属性
CommitLog是怎么工作的
- 写入消息:
- 根据MapedFileQueue.getLastMapedFile方法获取最后写的CommitLog文件映射,若都写满了或没有文件,则创建
- MapedFile.appendMessage(Object msg, AppendMessageCallback cb)方法将消息内容写入到消息缓存MappedByteBuffer,由后台服务负责刷盘逻辑
- 如果Broker是同步刷盘,并且消息的property属性中”WAIT”参数为空或者为TRUE,则利用GroupCommitService后台线程服务进行刷盘操作,具体刷盘操作为
- 构建GroupCommitRequest对象,其中nextOffset变量的值等于wroteOffset(写入的开始物理位置)加上wroteBytes(写入的大小),表示下一次写入消息的开始位置;
- 将该对象存入GroupCommitService.requestsWrite写请求队列中,并唤醒GroupCommitService线程将写队列的数据与读队列的数据交互(读队列的数据肯定是空);
- 该线程的doCommit方法中遍历读队列的数据,检查MapedFileQueue.committedWhere(刷盘刷到哪里的记录)是否大于等于GroupCommitRequest.nextOffset,若是表示该请求消息表示nextOffset之前的消息已经被刷盘,否则调用CommitLog.MapedFileQueue.commit(int flushLeastPages) 进行刷盘操作;
- 用MapedFileQueue的存储时间戳storeTimestamp变量值(在MapedFileQueue.commit方法成功执行后更新)更新StoreCheckpoint.physicMsgTimestamp变量值(checkpoint文件内容中其中一个值);
- 清空读请求队列requestRead;
- 如果Broker为异步刷盘(ASYNC_FLUSH),唤醒FlushRealTimeService线程服务。在该线程的run方法处理逻辑如下:
- 根据CommitLog刷盘间隔时间(默认是1秒)来间断性的调用CommitLog.MapedFileQueue.commit(int flushLeastPages)方法进行刷盘操作;
- MapedFileQueue的存储时间戳storeTimestamp变量值(在MapedFileQueue.commit方法成功执行后更新)更新StoreCheckpoint.physicMsgTimestamp变量值(checkpoint文件内容中其中一个值);
- 如果Broker为同步双写主用(SYNC_MASTER),并且消息的property属性中”WAIT”参数为空或者为TRUE,则等待监听主Broker将数据同步到从Broker的结果,若同步失败,则置PutMessageResult对象的putMessageStatus变量为FLUSH_SLAVE_TIMEOUT,监测方法如下:
- 检查主从数据传输是否正常。备用连接是否大于0,主用put的位置masterPutwhere等于wroteOffset(写入的开始物理位置)加上wroteBytes(写入的大小),masterPutwhere减去HAService.push2SlaveMaxOffset(写入到Slave的最大Offset)的差值不能大于256M,否则视为主备同步异常,置PutMessageResult对象的putMessageStatus变量为SLAVE_NOT_AVAILABLE;
- )若主备同步正常,则利用wroteOffset(写入的开始物理位置)加上wroteBytes(写入的大小)的值为参数构建GroupCommitRequest对象,即该对象的nextOffset值等于wroteOffset+wroteBytes;然后调用HAService.GroupTransferService.putRequest(GroupCommitRequest request)方法将请求对象放入 GroupTransferService服务的队列中,用于监听是否同步完成;再调用GroupCommitRequest.waitForFlush(long timeout)方法,该方法一直处于阻塞状态,直到HAService线程服务完成同步工作或者超时才返回结果;若GroupCommitRequest对象的flushOK变量为true则表示同步成功了,在GroupTransferService服务线程中判断是否同步完成的方法是用该对象中的nextOffset值与HAService.push2SlaveMaxOffset比较。
- 初始化DispatchRequest对象,其中包括topic、queueID、wroteOffset(写入的开始物理位置)、wroteBytes(写入的大小)、logicsOffset(已经写入的消息块个数)、消息key值等;调用putRequest(DispatchRequest dispatchRequest)将请求消息放入DispatchMessageService.requestsWrite队列中;由DispatchMessageService服务处理该请求;为请求中的信息创建consumequeue数据和index索引。
- 读取消息:
该方法的入参有两个:读取的起始偏移量offset和读取的大小size。首先调用findMapedFileByOffset方法根据起始偏移量offset所在的MapedFile对象;然后调用MapedFile对象的selectMapedBuffer方法获取从offset开始的size大小的消息内容;由于offset是commitlog文件的全局偏移量,要以offset%mapedFileSize的余数作为单个文件的起始读取位置传入selectMapedBuffer方法中。 - 正常状况恢复数据:
2. ConsumeQueue消息逻辑队列
消息逻辑队列文件,每个消息主题会有多个消息消费队列(MessageQueue),每个消息队列会有一个消息文件。它保存了该MessageQueue的所有消息在CommitLog文件中的物理位置(offset偏移量)
3. IndexFile
IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
同步刷盘/异步刷盘
Linux内存工作原理
Mmap和PageCache
RocketMQ的读写做法逻辑:
- 将数据文件通过Mmap(NIO中的MappedByteBuffer实现)映射到OS的虚拟内存中
- 当消息写入时,先写到PageCache,然后异步刷盘到磁盘
- 当消息消费者订阅消息时,要读取的数据也通过PageCache,由于PageCache一次读取4k,所以即使数据不到1k也会预加载4k到缓存中,这样下次读取的消息也容易在PageCache中命中。加快消息消费速度
Mmap
传统IO和Mmap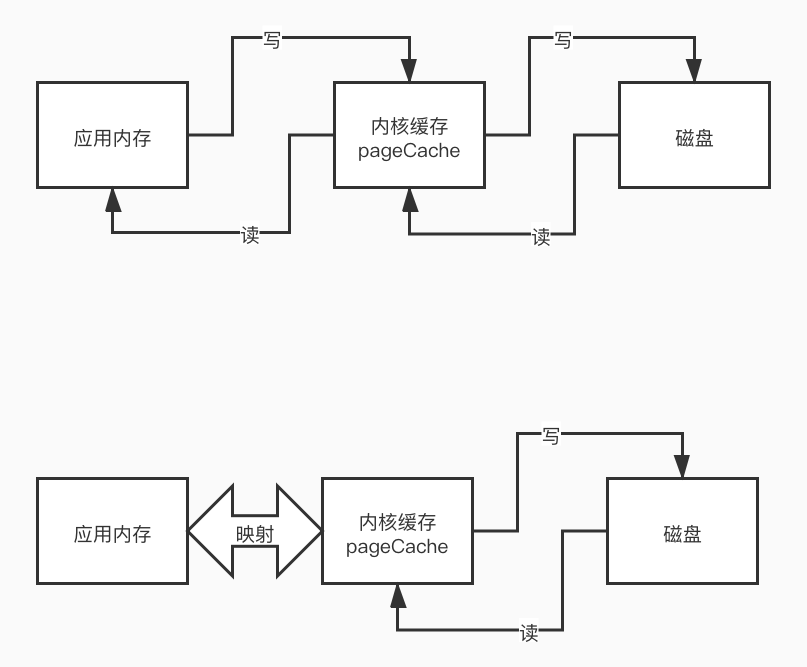
mmap基于OS的mmap内存映射技术,将文件直接映射到用户内存,使得对文件的操作不用再需要拷贝到PageCache,而是转化为对映射地址映射的PageCache的操作,使随机读写文件和读写内存拥有相似的速度(随机地址被映射到了内存)
注意点:mmap一次只能映射1.5-2G的文件,所以CommitLog限制1G大小。在映射完成后,会占用虚拟内存,并且释放回收后,虽然不占用物理内存了,但是还是会占用虚拟内存空间,回收比较麻烦。
PageCache
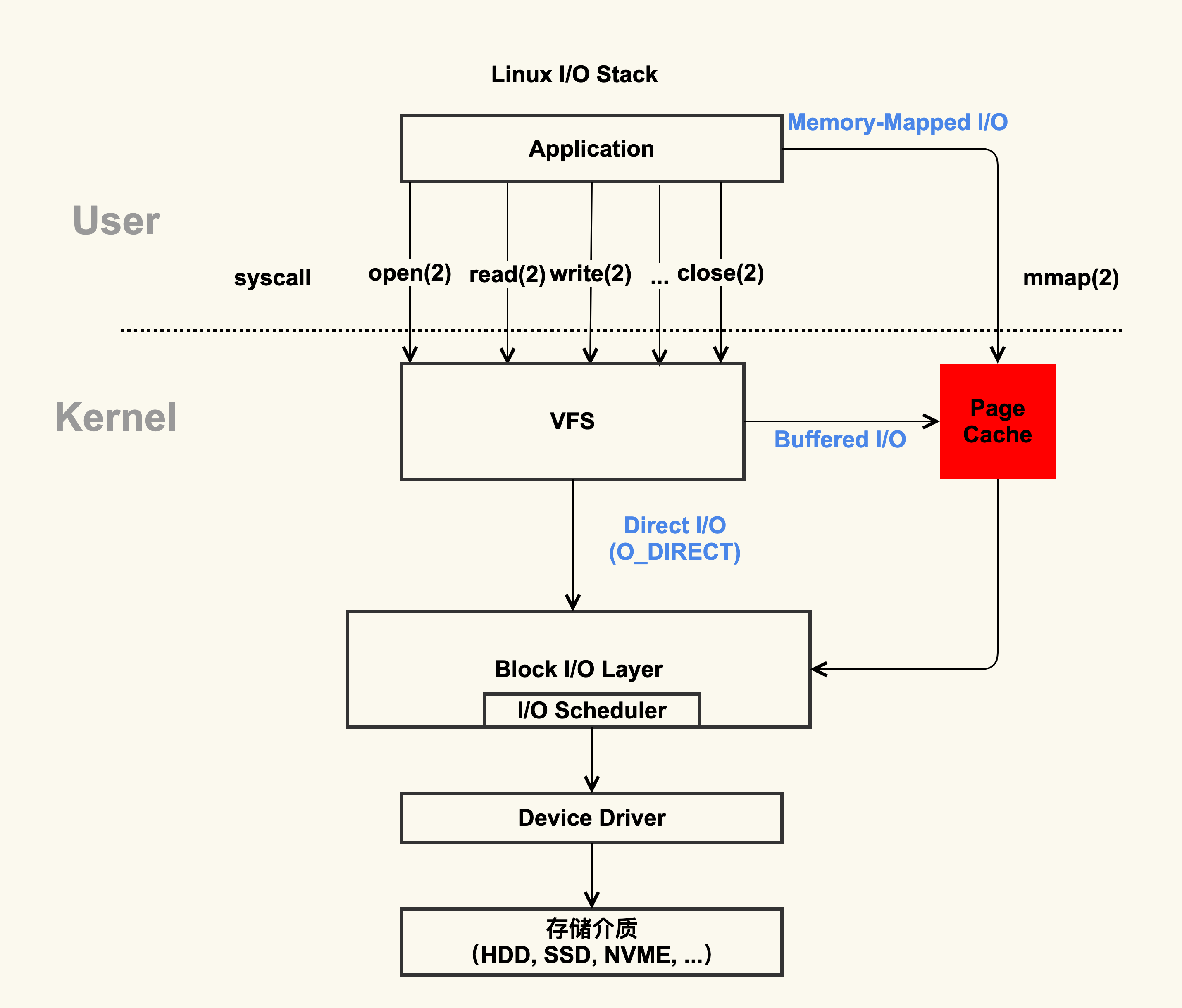
PageCache属于内核,它对于应用提升I/O效率是一个投入产出比很高的解决方案
源码分析
1 | // 发送消息 |