初探Java爬虫
既然学的是Java,那就用Java来学爬虫.
Demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public class spiderDemo {
public static void main(String[] args) {
String url = "https://www.baidu.com";
StringBuffer result = new StringBuffer();
BufferedReader in = null;
try{
URL readUrl = new URL(url);
URLConnection connection = readUrl.openConnection();
connection.connect();
in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String tempStr = "";
while ((tempStr = in.readLine())!=null){
result.append(tempStr);
}
System.out.println(result);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("爬取结束");
}
}
}
|
程序运行结果
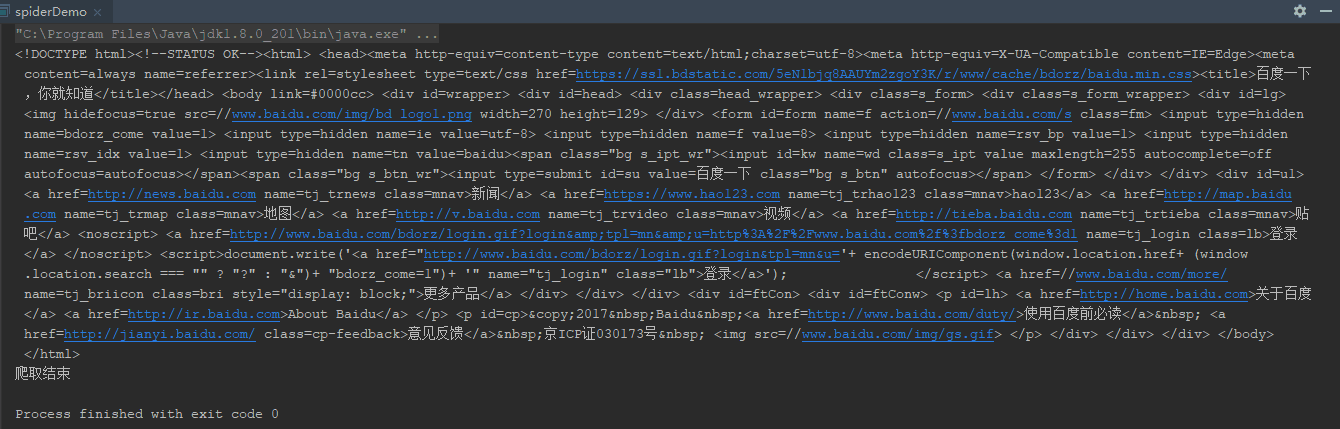
可以看到, 上述程序连接到URL,然后读取了响应, 也就是baidu首页的源码
那么如何获取更细的内容呢.
正则表达式的应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static void main(String[] args) {
SpiderDemo spiderDemo = new SpiderDemo();
String url = "https://www.baidu.com";
String result = spiderDemo.spiderMan(url);
String patternStr = "<img.*src\\s*=\\s*(.*?)[^>]*?>";
String targetStr = result;
Pattern pattern = Pattern.compile(patternStr);
Matcher matcher = pattern.matcher(targetStr);
while (matcher.find()){
System.out.println("匹配成功");
System.out.println(matcher.group());
}
}
|
正则表达式是爬虫获取精确内容的重要基础
Anything can go right will go right