并发容器类
(一)HashMap 源码分析
非线程安全容器类
1. 存储结构
HashMap 是依据哈希表(数组和链表的结合)实现的
内部使用 Node 类型的数组,即一个数组,数组的元素是链表
每一个 Node 都存储着四个字段,如下: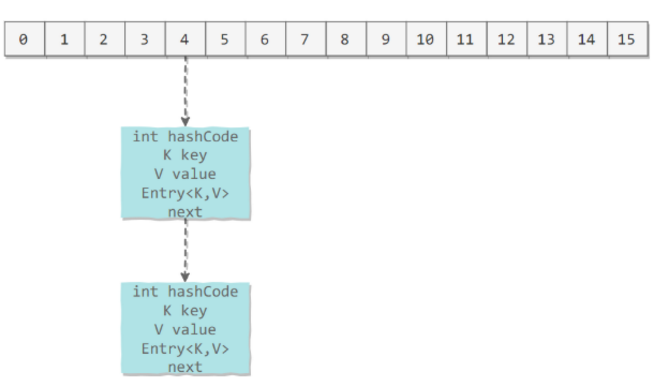
从 next 字段我们可以看出 Node 是一个链表.即数组中的每一个位置存储一个链表的头结点,HashMap 使用链表法来解决冲突,同一个链表中存放着 hash(key)%len( 元素 key 的哈希值和数组长度取模运算) 结果相同的元素
2. 拉链法的工作原理
拉链法: 就是把具有相同哈希值的关键字值放在同一个单链表中
比如
1 | // 新建一个默认大小16的HashMap |
3. JDK1.7 和 JDK1.8 中 HashMap 的区别
单链表数组结构的缺陷
JDK1.7 采用的是单链表数组的结构,这样的结构,在查找的时候是分为两步的;
- 先计算要查找的元素的键
key所对应的 hashCode,然后除留语法得到链表头所在数组的位置 - 然后从这个头结点,按顺序查找比对.
所以,单链表数组结构的查询算法的时间复杂度与链表的长度成正比,和数组的长度无关.
单链表数组的扩容机制
因为查询的时间复杂度与链表长度成正比, 所以需要尽量让链表保持较短
这就引入了扩容机制,扩大数组的长度,从而减少了链表的长度.
但是扩容机制成本非常大, 因为它需要新建一个长数组,然后把之前的每个节点都重新计算 hash 值,再复制到新数组中,构成新的链表数组
扩容机制的新数组长度为旧数组的两倍, 这就保证了旧数组中的节点所在位置 index 在新数组中,要么还是 index,要么就是 index+oldTable.lenth()
JDK1.8 的红黑树
由于扩容机制的成本太大,所以 JDK1.8 中引入了红黑树的数据结构,它是一种自平衡二叉树,它不要求平衡二叉树那样的绝对平衡,但是每次添加操作,都能保证只做三次旋转,就能达到自平衡二叉树的要求,而平衡二叉树插入新节点的旋转次数却不可预知。
红黑树保证了用少量的算力换取相对的平衡。
在 JDK1.8 中设计了每个链表长度都有阈值,超过阈值后,链表就会转换成红黑树。以降低时间复杂度和减少扩容次数。
头插法和尾插法
JDK1.7 采用头插法,但是由于每次插入操作之前,都会遍历一遍链表,已判断是更新还是插入,所以头插法并没有提高插入效率 ,其次可能是考虑到新插入的元素更可能被先使用,所以使用头插法,让先头插法让新插入的元素更容易的被查找到
JDK1.8 开始采用尾插法
- 是因为 JDK1.7 中的扩容机制,是从表头开始复制到新数组,这就和原来的旧的链表相反了, 由于头插法, 后插入的数据本来应该在表头,可是复制到新数组中成了链表的尾结点. 这使得新插先用的想法成为了伪命题.
- 头插法在并发情况下,容易造成循环链
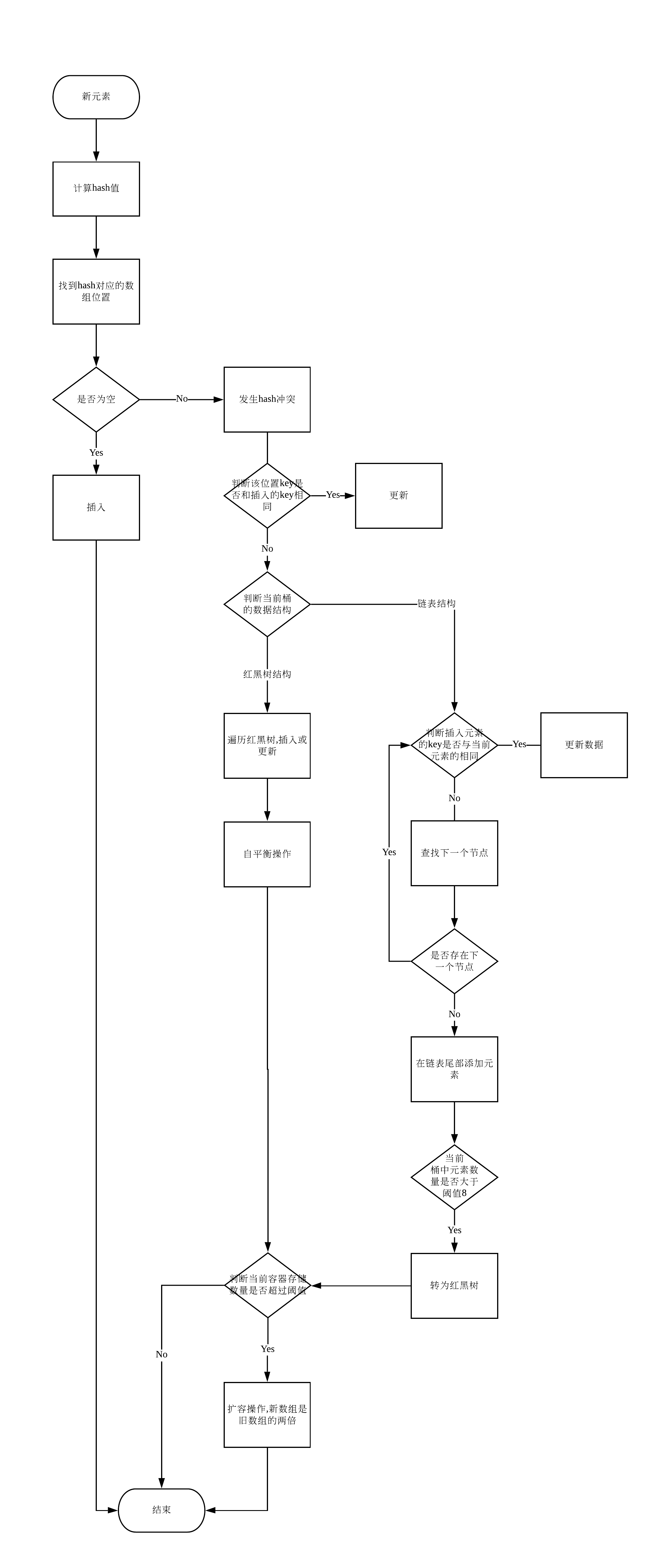
HashMap 在 JDK1.8 中的简单流程
(二)HashTable
一个 synchronized 的 HashMap,只是在 HasMap 上加了 synchronized 关键字,它是遗留类,现在不推荐使用,因为全程都是重量级锁
它不允许记录的键或者值为空
(三)ConcurrentHashMap 源码分析
ConcurrentHashMap 支持线程安全,并且 ConcurrentHashMap 的效率会比 HashTable 更高,因为它引入了分段锁。
ConcurrentHashMap存储结构
在 JDK1.7 中Segment<K,V>[]Segment<K,V>对象中含有HashEntry<K,V>[]table 数组
每一个 Segment 都是一把锁
结构如图: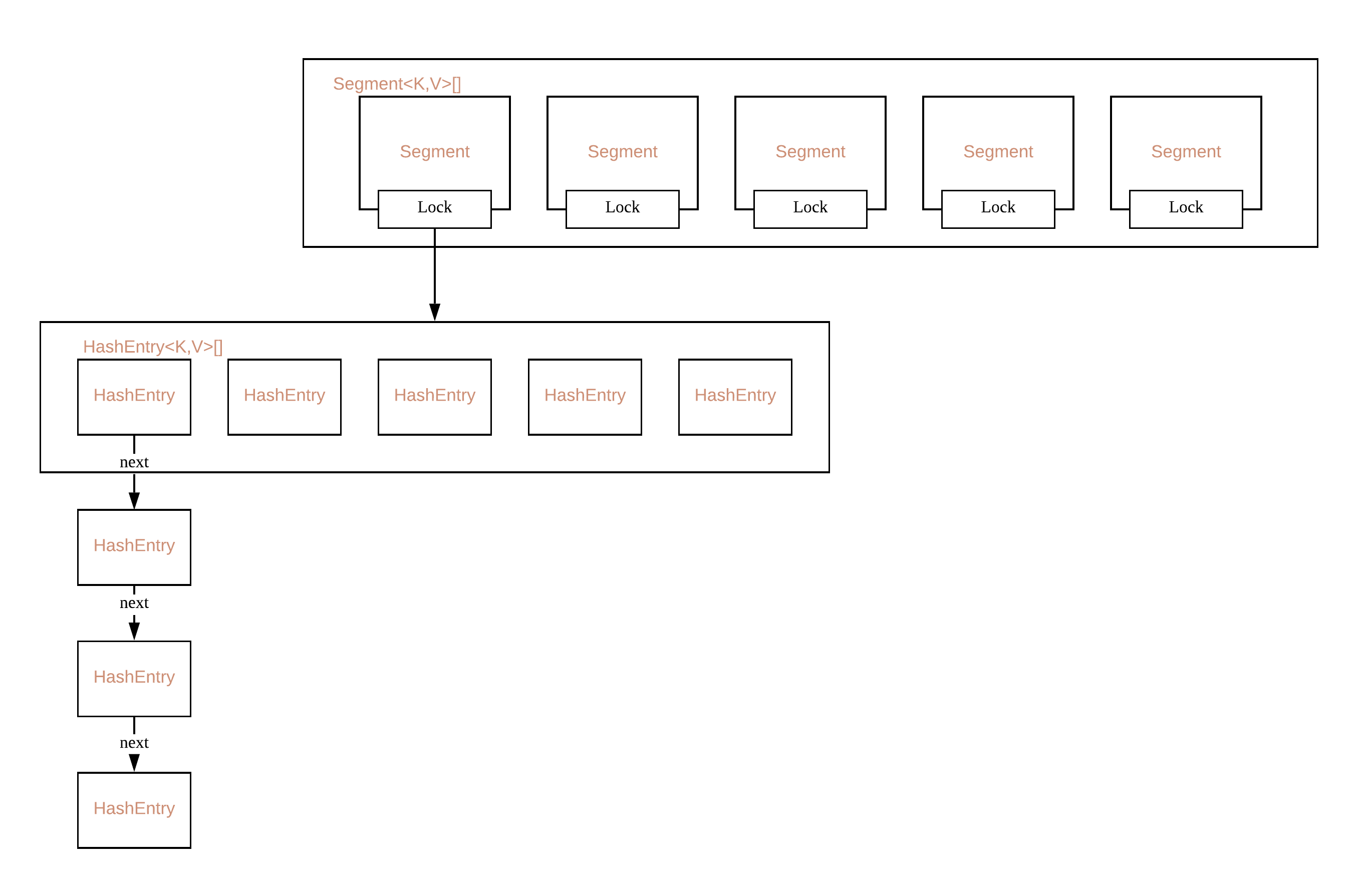
在 JDK1.8 中
结构和 HashMap 类似,但操作的时候,产生 Hash 冲突时,对于当前的桶的头结点加锁.没有 Hash 冲突时采用 CAS 机制来操作数组
hash 冲突的几率是小的,JDK1.8 的设计,减少了加锁次数和加锁范围, 只有 hash 冲突时加锁,且只加在一个桶
(四)ArrayList
ArrayList存储结构
ArrayList 是基于数组实现的,默认的大小是 10, 它继承了 RandomAccess 接口, 意味着支持随机访问
自动扩容
size 属性记录了保存的元素数量,当容量不够时就会扩容
新的数组长度是 oldCapacity+(oldCapacity>>1),也就是原来的 1.5 倍
扩容时会把所有元素复制到新数组,代价很高, 所以最好能在一开始就知道要存的量,并在初始化的时候指定大小
modCount 标记位
ArrayList 有一个 modCount 标记位, 用来记录修改移除添加的操作的次数, 当利用迭代器对它进行遍历操作时, 会拷贝一个 expectModCount, 用来判断是否有修改操作, 当 ArrayList 被修改(修改,添加,移除),modCount 和 expectModCount 不一致, 就会抛出异常
(五)CopyOnWriteArrayList
ArrayList 的并发版本,由 J.U.C 包提供,采取读写分离的思想
添加数据的时候执行加锁,然后(拷贝原数组, 添加元素, 再替换),保证这些操作的线程安全
但这样做有两个问题:
- 占用内存, 因为会复制一份完整的数组
- 读取会有时间滞后性, 其他线程进入读操作,读到的是旧数组的内容. 要替换操作完成, 才能读到
(六)Vector
同步关键字版本的 ArrayList,遗留容器
(七)HashSet
基于 HashMap 实现 Set 与 List 的区别是,Set 元素不能重复, 这也叫就是 HashMap 的一个特性
HashSet存储结构
内部有一个 HashMap
(八)CopyOnWriteArraySet
基于 CopyOnWriteArrayList
基本原理就是添加时先进行比对操作,没有重复值才插入
(九)PriorityQueue
采用数组结构, 引入完全二叉树概念
所以是有序队列
(十)LinkedList
双链表结构
前指针
数据类型
后指针